The varying significance of distinct primitive behaviors during the policy learning process has been overlooked by prior model-free RL algorithms. Leveraging this insight, we explore the causal relationship between different action dimensions and rewards to evaluate the significance of various primitive behaviors during training. We introduce a causality-aware entropy term that effectively identifies and prioritizes actions with high potential impacts for efficient exploration. Furthermore, to prevent excessive focus on specific primitive behaviors, we analyze the gradient dormancy phenomenon and introduce a dormancy-guided reset mechanism to further enhance the efficacy of our method. Our proposed algorithm, ACE: off-policy Actor-critic with Causality-aware Entropy regularization, demonstrates a substantial performance advantage across 29 diverse continuous control tasks spanning 7 domains compared to model-free RL baselines, which underscores the effectiveness, versatility, and efficient sample efficiency of our approach.
Here we provide visualizations of the ACE agent's behaviors on a variety tasks.
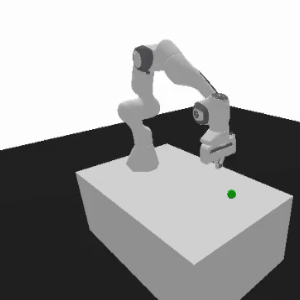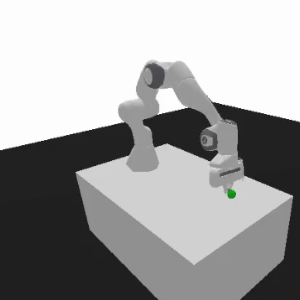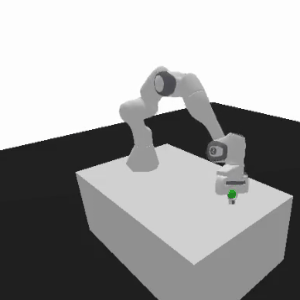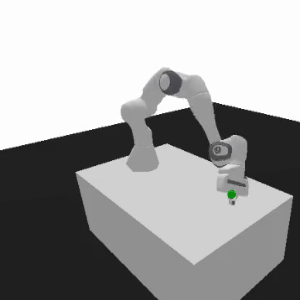
Motivating example
This task involves a robotic arm hammering a screw into a wall.
Initially, the robotic arm approaches the desk moving on the z-axis and struggles with torque grasping, making z-axis positioning and torque exploration a priority.
As the training advances, the agent's focus shifts to optimizing movement, prioritizing end-effector position (x-axis and y-axis improvement).
Finally, potential improvements lie in the stable and swift hammering, shifting focus back to torque and placing down the object.
The evolving causal weights, depicted on the left, reflect these changing priorities.
Benchmarking
Manipulation tasks. We conducted experiments on
tabletop manipulation tasks in MetaWorld, tackling 14 tasks
with dense rewards, spanning 4 very hard, 7 hard, and 3
medium tasks, including all types of tasks and all levels of
task difficulties.
Locomotion tasks. We conducted experiments on four MuJoCo tasks
and five DeepMind Control Suite tasks, encompassing diverse embodiments.
Dexterous hand manipulation tasks. We compare ACE with baselines on
three dexterous hand manipulation tasks, including
Adroit and Shadow Dexterous Hand suites.
Sparse reward tasks. We evaluate our approach
against baselines on tasks with sparse rewards.
These tasks pose significant challenges for online RL exploration, covering
both complex robot locomotion (Pandagym and ROBEL) and manipulation (MetaWorld).
Citation
@article{ji2024ace,
title={ACE: Off-Policy Actor-Critic with Causality-Aware Entropy Regularization},
author={Ji, Tianying and Liang, Yongyuan and Zeng, Yan and Luo, Yu and Xu, Guowei and Guo,
Jiawei and Zheng, Ruijie and Huang, Furong and Sun, Fuchun and Xu, Huazhe},
journal={arXiv preprint arXiv:2402.14528},
year={2024}
}